
About this article
In this article, we talk about entities, attributes, and relationships. We explore how we can discover them in the business domain and how they relate to tables, columns, and relationships in the database domain.
This the second post on a series exploring the subject of relational database design for the full-stack developer.
For quick access, here is the list of all the articles on the topic:
- Introduction to Relational Databases
- Database Design: Entities, Attributes, and Relationships (this article)
- Database Design: Entity-Relationship Diagrams
- Database Design: Normalization
- Database Design: Entity-Relationship Diagram to Structured Query Language
- Deploying PostgreSQL for development and testing
- Structured Query Language Cheat Sheet
- Working with databases from Python
Introduction
As a full-stack developer, you work on many programming projects that required a database. For some of them, you use an existing database. For others, however, you must design and implement a database from scratch.
The quality of your database design has a direct impact on the quality of your final application. A well-designed database that accurately models the business domain entities results in software that is sturdy, reliable, and fast.
In this post, we use an example to illustrate how to discover entities, attributes, and relationships from a problem statement provided by a client. This discovery is a necessary first step for designing a relational database for a full-stack project.
This article relies on the process described by Fidel A. Captain in his excellent book “Six-Step Relational Database Design.” You should reference this book for a more in-depth look at relational database design.
Problem Statement
Before any database design takes place, you must obtain from your client a problem statement. The statement should clearly express the business problem you are solving and the data your application should track.
It is crucial to get the problem statement right. It should be concise while avoiding to omit important details.
Case Study: Atelier-M Store
Atelier-M Store sells personalized leather accessories on Instagram. The store posts product pictures and customers place orders following a link to a Google Form.
Sales are good, and the current method for taking and tracking orders is limiting further growth. Atelier-M hired you to build an online store.
The problem statement follows:
A small shop wants an online store to sell personalized leather accessories. The store application must keep track of the following:
- The customers
- The orders placed by customers and the details of the orders
- The products
- The personalizations requested on the products
- The packages requested for each product in the orders
- The payments received for the orders
- If the order is a gift, we must track the cards selected and the personalized messages that should be handwritten on the cards
- The staff that can access the store’s admin dashboard
- The delivery options
- The delivery addresses for the orders
Discover Entities and Assign Attributes
Entity Identification
Once you have the problem statement, the first step is to identify the entities the app must track. Entities are objects of interest in the business domain. They map to tables in the database and classes in code.
You can find entities in the problem statement by spotting nouns or collective nouns. Applying this technique in our case study, we get:
A small shop wants an online store to sell personalized leather accessories. The store application must keep track of the following:
- The customers
- The orders placed by customer sand the details of the orders
- The products
- The personalizations requested on the products
- The packages requested for each product in the orders.
- The payments received for the orders
- If the order is a gift, we must track the cards selected and the personalized messages that should be handwritten on the cards
- The staff that can access the store’s admin dashboard
- The delivery options
- The delivery addresses for the orders
This exercise produces an initial list of entities as follows: customers, orders, order details, products, personalizations, packages, payments, cards, messages, staff, delivery options, and addresses.
Refining the list, you could argue that customers and staff are application users with different roles and permissions. So, you can replace customers and staff with users and add entities for roles and permissions.
Now, let’s take a look at cards and messages. A customer places an order as a gift. In that case, the order would include a card with a handwritten message.
There are several types of cards to select from (i.e., birthday, Christmas, and so on), and your client could add new card types in the future. To accurately track them, cards should be an entity.
On the other hand, a gift order has one message. The customer enters the message text when placing the order. In this case, you should track the messages as attributes of orders.
Regarding addresses, you may think of them as attributes of users. However, users can place orders for delivery to different addresses (i.e., home, work, and so on), and attributes should describe one and only one characteristic of an entity. It is clear then that you must track addresses as an entity.
Pro Tip: About Naming Conventions
In a future article, we implement the database design from this series in PostgreSQL. For this reason, it is helpful to use PostgreSQL naming conventions for tables and columns while discovering entities and entity attributes. The naming rules we follow are:
- All identifiers are lowercase words (i.e., username).
- If an identifier consists of several words, we use an underscore to separate each word in it (i.e., last_name).
- Identifiers for table names are plural nouns (i.e., order_details).
- Identifiers for table columns are singular nouns (i.e., quantity).
If you are implementing your design in other RDBMS, use the naming conventions for that system.
The final list of entities after applying our naming convention is users, roles, permissions, orders, order_details, products, personalizations, packages, payments, cards, delivery_options, and addresses.
Attribute Assignment
Attributes are properties that describe an entity’s characteristics. Attributes map to database table columns, and as mentioned in Introduction to Relational Databases, both table columns and attributes should describe precisely one property of the entity.
The process of identifying attributes can be long and tedious. Meetings with the client and client’s staff are necessary to capture relevant attributes.
Reviewing the client’s processes, primarily process documentation, forms, and records kept either on paper or by electronic means, is essential for complete identification of all attributes.
In our case study, customers place orders by filling a Google Form. A Google Sheet captures the results from each form’s submission. From the study of this Google Sheet’s structure and meetings with your client, you come up with the following list of attributes for each of the discovered entities.
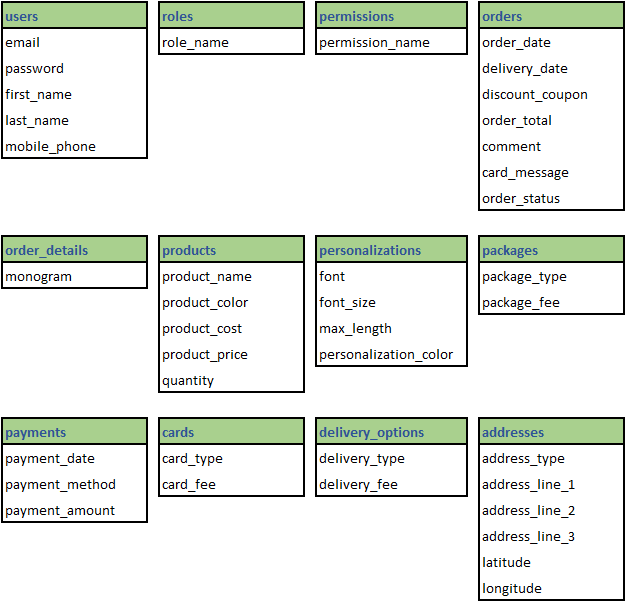
We used Excel to build list of entities and attributes for Atelier-M store’s database
Once you finish identifying attributes for the entities, you should search for candidate attributes for primary keys. A primary key is an attribute or a set of attributes that uniquely identifies an instance of an entity.
For example, in your entity users, you could select email as a candidate primary key. After all, emails are unique and identify a particular user.
There is a problem, however, with that primary key. People can, and often do, change emails. If a user changes the email, records related to the old email become orphaned.
A common practice for assigning primary keys is to add an id attribute to each entity. The id auto-increments with each new instance of the entity, ensuring its uniqueness.
For the case study, you use precisely this technique and end up with the following diagram:
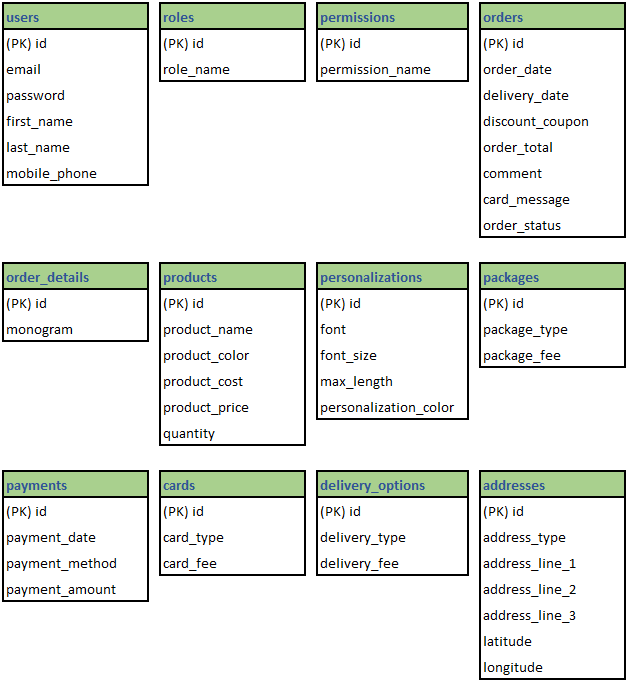
Entities and Attributes with Primary Keys for Atelier-M store’s database
Derive Relationships
Now that you have a clear picture of the entities and their attributes, you can proceed with exploring the relationships between entities. For this task, you use an Entity-Entity Matrix.
An Entity-Entity Matrix is just a table where both the column headings and the row headings are the entities discovered in the previous step.
For the case study, using Excel, you build the following Entity-Entity Matrix:
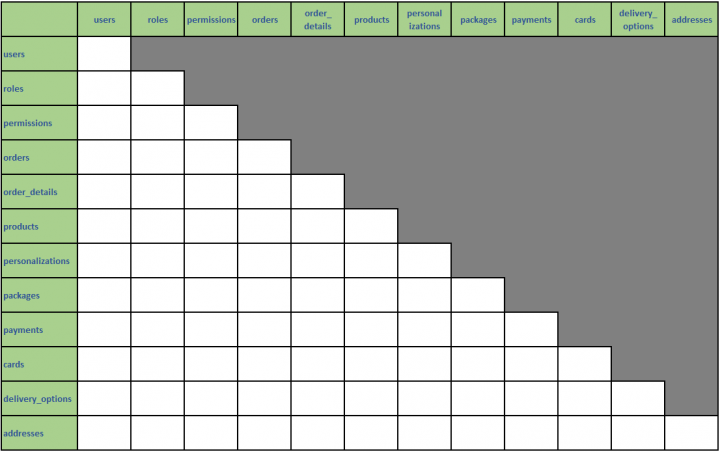
We used Excel to build this Entity-Entity Matrix
It is important to note that you only use the bottom half of the matrix. Since each half of the matrix mirrors the other, using both would be redundant.
Each cell in the matrix holds the relationship between the entities in its row and column. You should identify these relationships and write in each cell a verb that represents it.
If there is no relationship between two entities, leave the cell blank.
The resulting Entity-Entity Matrix for our case study follows:

Finished entity-entity matrix for Atelier-M database
Going over the matrix cell by cell, you can state:
- Users have roles
- Roles have permissions
- Users place orders
- Order details belong to orders
- Order details contain products
- Products have personalizations
- Orders use packages
- Orders have payments
- Orders use cards
- Orders have delivery options
- Addresses belong to users
Pro Tip: Unary Relationships
Note that in our exercise, no entity is related to itself. Keep in mind that those relationships (known as unary relationships) sometimes exist. One example would be the users’ entity in a social media application where users follow users.
Conclusion
In this article, you discovered the entities, attributes, and relationships for the database design of an online store. In the next article, you will use this information to create an entity-relationship diagram for implementation in PostgreSQL.
References
- “Six-Step Relational Database Design.” by Fidel A. Captain
- Difference Between Entity and Attribute in Database
- PostgreSQL naming conventions
- Relational database design question – Surrogate-key or Natural-key?
- N-ary relationship types
You may also like: